Идея превратить YouTube в личное облачное хранилище звучит одновременно гениально и безумно. Бесплатный хостинг с практически неограниченным объёмом, надёжная инфраструктура Google, CDN для быстрой раздачи — казалось бы, идеальное решение для бэкапов. Но между концепцией и реализацией лежит пропасть из технических ограничений, юридических рисков и практических проблем. Давайте разберём, как работает эта технология, почему она существует и почему её не стоит использовать.
Принцип работы: от байтов к пикселям
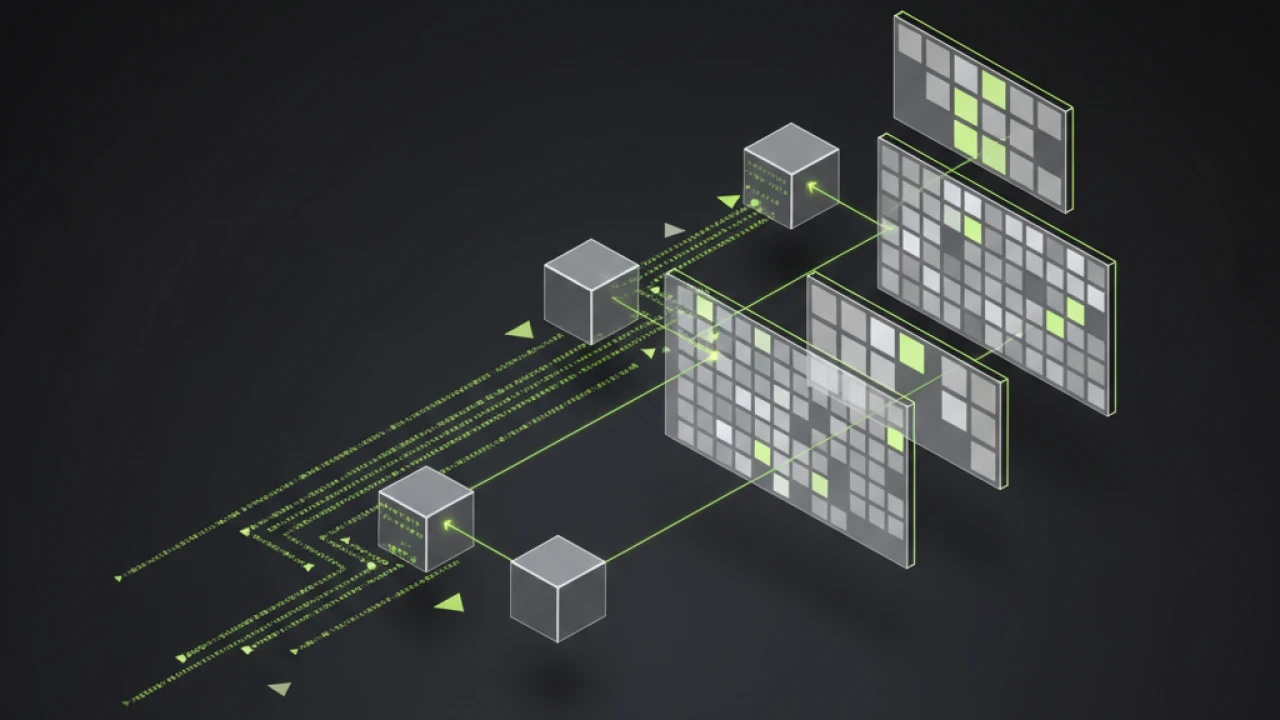
Базовая идея элегантна в своей простоте. Любой файл — это последовательность байтов, каждый байт — число от 0 до 255. RGB-пиксель видео — это три канала цвета, каждый принимает значения от 0 до 255. Соответствие идеальное: один пиксель хранит три байта данных.
Алгоритм кодирования выглядит так:
- Читаем файл побайтово
- Группируем байты по три
- Каждую тройку превращаем в RGB-значение пикселя
- Формируем кадры видео из пикселей (например, 1920×1080 даёт 6 МБ на кадр)
- Собираем кадры в видеофайл
- Загружаем на YouTube
Обратный процесс симметричен: скачиваем видео, извлекаем кадры, читаем RGB-значения, восстанавливаем байты. В теории — безупречно. Видео в Full HD при 30 FPS даёт пропускную способность около 180 МБ в секунду чистых данных. Час такого видео — это 648 гигабайт. YouTube позволяет загружать видео до 12 часов — получается почти 8 терабайт на одно видео.
Проблема сжатия: когда математика ломает данные
Реальность жестока: YouTube не хранит загруженные видео как есть. Каждый файл проходит перекодирование в H.264 или VP9 — современные кодеки с lossy-сжатием. Они оптимизированы для реальных видео: ищут повторяющиеся паттерны между кадрами, устраняют незаметные для глаза детали, агрессивно сжимают высокочастотные компоненты.
Наше "видео" из случайных пикселей — это худший кейс для таких алгоритмов. Нет паттернов, нет предсказуемости, каждый пиксель уникален. Кодек всё равно применяет сжатие, искажая значения. Результат: часть байтов меняется, файл становится нечитаемым.
В видеоролике выше разбираем практический эксперимент с кодированием тестового файла и измерением процента искажённых байтов после загрузки на YouTube. Спойлер: без защиты от ошибок теряется до 15% данных.
Reed-Solomon коды: математика против деградации
Решение проблемы — коды с исправлением ошибок. Reed-Solomon коды используются в QR-кодах, CD/DVD-дисках, системах спутниковой связи. Принцип: добавляем к данным избыточную информацию, которая позволяет восстановить оригинал даже при частичном повреждении.
Математика выглядит сложно, но идея проста. Представьте, что исходные данные — это коэффициенты полинома. Мы вычисляем значения этого полинома в нескольких точках и добавляем их к данным. При декодировании, даже если часть значений испорчена, полином можно восстановить через интерполяцию — достаточно знать определённое количество корректных точек.
Практическая реализация:
from reedsolo import RSCodec
rs = RSCodec(nsym=30)
# Кодируем блок данных
encoded = rs.encode(original_data)
# Декодируем с исправлением ошибок
decoded = rs.decode(corrupted_data)[0]Цена защиты — overhead. Для уровня коррекции в 30% каждый килобайт данных требует 1.3 КБ в закодированном виде. Учитывая контейнер видео, метаданные, потери при сжатии, реальная эффективность хранения падает до 40-50%. Терабайт данных превращается в 2-2.5 терабайта видео.
Архитектура решения: от CLI до метаданных
Типичная реализация — CLI-утилита на Python с несколькими компонентами:
Энкодер использует OpenCV для генерации кадров. Файл разбивается на блоки по 6 МБ (размер кадра 1920×1080), каждый блок проходит через Reed-Solomon кодирование, затем конвертируется в RGB-массив. Массивы склеиваются в видео через FFmpeg с минимальным CRF (constant rate factor) для снижения потерь.
Загрузчик работает через YouTube Data API v3. Требуется OAuth-авторизация, получение токена, затем multipart-загрузка видеофайла. API возвращает video ID, который сохраняется в локальную базу метаданных.
Метаданные критически важны. Для каждого файла нужно хранить:
- Оригинальное имя и расширение
- SHA-256 хеш для верификации целостности
- YouTube video ID
- Параметры кодирования (размер кадра, уровень коррекции)
- Порядок чанков, если файл разбит на несколько видео
База метаданных обычно реализуется через SQLite. Без неё восстановление данных невозможно — по видео нельзя определить, что это за файл и как его декодировать.
Декодер скачивает видео через youtube-dl или yt-dlp, извлекает кадры через OpenCV, читает RGB-значения, применяет Reed-Solomon декодирование, собирает байты обратно в файл. Финальная верификация через сравнение хешей.
Юридические и практические риски
Terms of Service YouTube однозначны: сервис предназначен для "загрузки, просмотра и распространения видеоконтента". Использование платформы как файлового хранилища прямо нарушает правила. Последствия:
- Блокировка аккаунта без предупреждения
- Удаление всех загруженных видео
- Возможный бан связанных устройств и email-адресов
- Отсутствие права на апелляцию (решение Google окончательно)
Автоматические системы детектирования злоупотреблений могут заметить паттерны: множество длинных видео с визуальным шумом, отсутствие просмотров, подозрительная регулярность загрузок. Даже если первые попытки пройдут, масштабирование привлечёт внимание.
С точки зрения надёжности это провал. Облачные провайдеры предоставляют SLA с гарантиями доступности 99.9%+. YouTube не даёт никаких гарантий для пользовательского контента. Видео могут удалить по DMCA-жалобе (даже ложной), из-за ошибок автоматической модерации, при изменении политики платформы.
Альтернативы и легитимные решения
Если цель — дешёвое хранение больших объёмов, существуют специализированные сервисы:
Backblaze B2 — $5 за терабайт в месяц, S3-совместимый API, без ограничений на размер файлов. Первые 10 ГБ бесплатно.
Wasabi — $6.99 за терабайт, без платы за egress (исходящий трафик), что критично для частого скачивания.
AWS Glacier Deep Archive — $0.99 за терабайт, но с задержкой восстановления до 12 часов. Подходит для архивных копий.
Для некоммерческого использования есть бесплатные варианты:
- Mega — 20 ГБ бесплатно с end-to-end шифрованием
- Yandex Disk — 10 ГБ, интеграция с экосистемой Яндекса
- pCloud — 10 ГБ с возможностью расширения через рефералов
Для распределённого хранения — блокчейн-решения типа Filecoin или Storj, где вы платите криптовалютой за гарантированную доступность данных на узлах сети.
Образовательная ценность vs продакшн-использование
Несмотря на непрактичность, проект кодирования файлов в видео имеет высокую образовательную ценность. Это hands-on практика в:
- Обработке медиа: работа с OpenCV, FFmpeg, понимание форматов контейнеров и кодеков
- Теории кодирования: реализация Reed-Solomon кодов, понимание избыточности и исправления ошибок
- API-интеграции: OAuth-авторизация, работа с YouTube Data API, обработка rate limits
- Системном дизайне: проектирование CLI-утилит, управление метаданными, обработка edge cases
Для студентов и начинающих разработчиков это отличный pet-project. Но попытка использовать в продакшене гарантированно закончится потерей данных или блокировкой аккаунта.
Заключение
YouTube как облачное хранилище — это технический эксперимент, демонстрирующий креативный подход к решению проблемы, но не жизнеспособное решение. Низкая скорость кодирования/декодирования, значительный storage overhead, юридические риски и отсутствие гарантий делают этот подход непригодным для реального использования.
Если вам нужен надёжный бэкап — используйте специализированные сервисы. Они стоят копейки, предоставляют API, гарантии доступности и техподдержку. Если хотите изучить обработку медиа и коды коррекции ошибок — реализуйте такой проект, это действительно интересная задача. Но не храните там ничего важного.
Технологии должны решать проблемы, а не создавать новые. В случае с YouTube-хранилищем баланс явно не в пользу практичности.